Kloth Architecture
The Kloth Architecture is a novel computer system architecture ("Heterogeneous Accelerated Compute") that builds on top of the Harvard Architecture to alleviate bottlenecks, particularly those between processors and accelerators as well as smart memory to share data if the Message Passing Interface (MPI) is used. The Kloth Architecture consists of multiple elements within a processor, its cores(s), an accelerator and its cores, and the smart memory.
We call the architecture "Heterogeneous Accelerated Compute" because it is heterogeneous (i.e. it allows for the integration of any core or accelerator), it largely assumes the execution of workloads in accelerators instead of in software on a CPU, and it retains the flexibility by using CPUs and their cores to direct the flow of the instructions and function calls.
It adds a scale-out port to the CPU (and accelerator) core that can be a virtual (prioritized) port, or a physical port to allow for Inter Processor Communication (IPC) across cores to be prioritized and executed with lower latency than a general-purpose port connected to a bus, torus or a mesh. It usually also involves a switch fabric as an interconnect between the cores and the fast IPC Input/Output (I/O). The I/O in our case is also equipped with switch fabric to route I/O traffic accordingly.
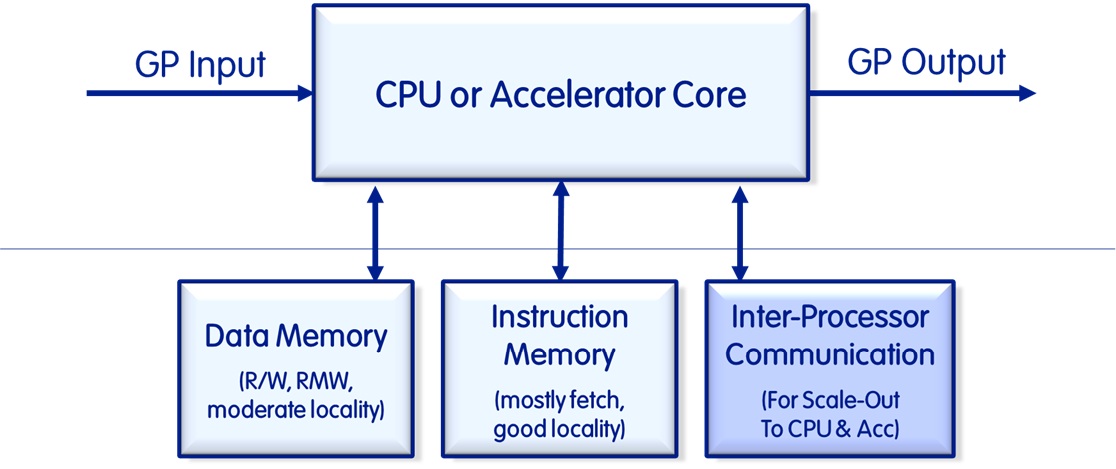
All IPC, DMA and RDMA transfers and requests become trivial with this architecture such that bulk I/O can be executed without any CPU involvement other than setting up the parameters. With TLBs present in the processors, accelerators and the smart memory, this is really a distributed set of I/O Memory Management Units (IOMMUs), and that means that transfer of data using physical or logical addresses (or a mix thereof) can be executed from any one of the participants of the data exchange.
A sample implementation of the architecure in our Server-on-a-Chip (or more precisely the Server Module) looks like the following:
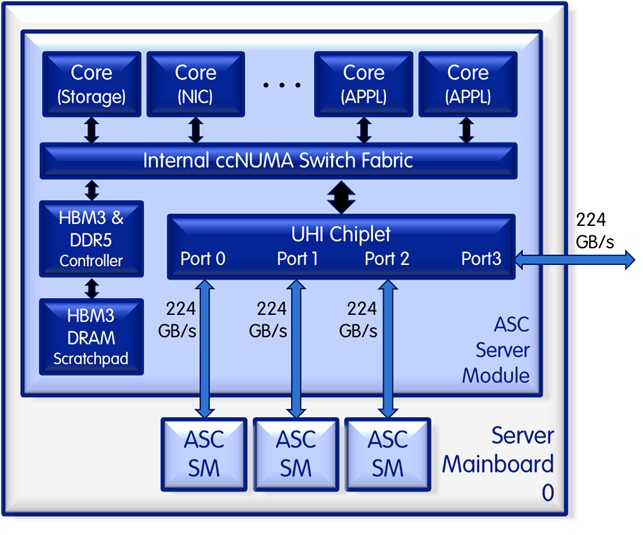
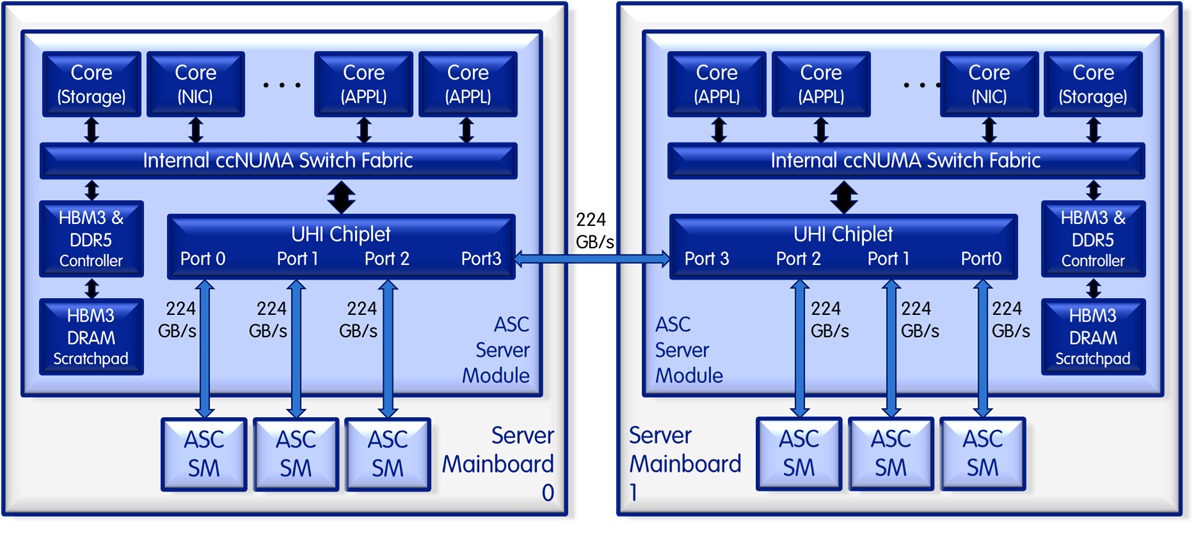
The Server-on-a-Chip (or more precisely the Server Module) allows for a dual processor and even a quad processor implementation without an external ccNUMA switch fabric as follows.
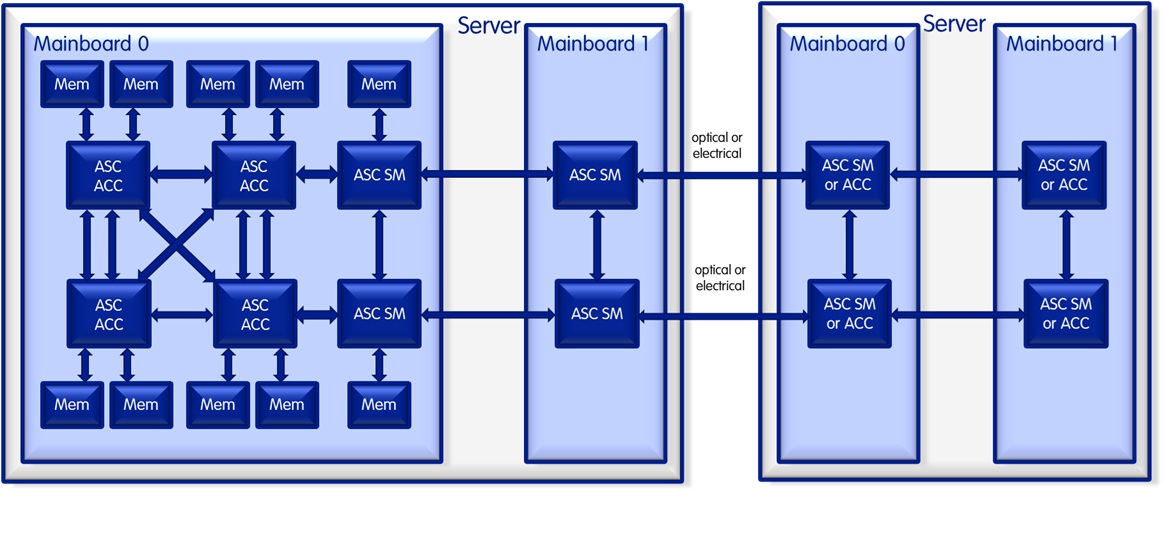
Our portfolio as a whole allows for the seamless integration of processors, accelerators and the smart memory using the same unified interface, again without the need for an external ccNUMA switch, in a direct point-to-point connectivity, with the ability to aggregate or parallelize multiple UHI ports. We call that port trunking, and it can be used if a single UHI port does not provide enough bandwidth between any two units.
The technology currently is in its final stages of logic implementation, whereas the patent was filed in July of 2024 (as US 2025/0036589 A1) with that priority date, and it was published in January of 2025.